Workshop 1
This workshop will introduce you to working with R as a statistical programming and analysis language, as well as going through the basics of how to use the RStudio editor which is a convenient and helpful interface to R.
1 R and RStudio
R is an open source programming language for statistical computing and graphics that is widely used among statisticians for data analysis. As R is a programming language and not a program itself (like Excel) we will need some programming skills, as even the simplest data analysis will require writing and evaluating small fragments of code to carry out the analysis we require. To make life easier, we will be using RStudio as an interface to write, edit, and evaluate our R code.
Both R and RStudio are available on the University network, via AppsAnywhere. Open the AppHub, search for “RStudio”, and launch it. It may take a little while to load fully the first time, so be patient.
But it is best to install R and RStudio locally on your computer. Both are free to download from the links below. Notice that you need to download R first then RStudio.
\(~\)
1.1 RStudio environment
When the program starts, a new window will open. You’ll now see that the default RStudio environment is divided in 4 panels, with the default arrangement illustrated below. Going anticlockwise, the four panels are: Code; Console; Plots, Help, and Files; and Workspace and History.

Code Editor – the main editor for your R code. This should contain the workshop script file that you have just downloaded and opened. This pane is hidden at first, however when you load or start a new R script file it will be displayed. R code can be entered here, and it provides support such as auto-complete using
[Tab], colour highlighting, and additional buttons and menu items to help edit and evaluate your code. In particular, a single line of code (or any selected block of code) can be evaluated in one go by typing[Ctrl]+[Enter], and the whole file can be evaluated with[Ctrl]+[Shift]+[S].R Console – this pane is where your code from the Editor is evaluated by R. You can also use the console here to execute quick calculations that you don’t need to save. Commands entered in the Console tab are immediately executed by R, and the results displayed on the following line. In this way, R can be used as a simple calculator by typing directly into the Console window. However, for more complex calculations with many steps it is preferable to write the code in a script file using the Code pane first, and then evaluate it in the Console. Note: when in the Console pane, you can use the (up arrow) and (down arrow) keys to navigate through previous commands (e.g. to correct mistakes).
Plots, Help, and Files – this pane has multiple roles indicated by the tabs along its top. The Plots tab will show the results of any plots you produce in R. The Help tab is where RStudio will display any help files. The Files tab provides a simple file viewer to quickly navigate between and open files.
Workspace and History – this pane has two functions, also indicated by tabs. The Workspace (or Environment) tab lists all the variables you have currently available in this session of R, along with their types and values. The History tab shows a list of all the R commands you have evaluated in the console.
2 Getting Started
2.1 First steps
When we just want to do small and quick calculations, we can type R commands directly into the console window. These commands will be evaluated immediately and the answer returned on the next line.
Let’s try some simple arithmetic:At the > prompt in the console you can type numerical expressions as you would into a calculator, hit R will print the answer.
R can be used as a calculator to perform the usual simple arithmetic operations. The operators are:
+addition-subtraction*multiplication/division^raise to the power (alternatively**also works)%%modulus, e.g.5 %% 3is2%/%integer division, e.g.5 %/% 3is1
Many standard mathematical functions are also available:
abs(x)- the absolute value ofxsqrt(x)- the square root ofxlog(x)- the natural logarithm ofx(uselog10for base-10)exp(x)- the exponential ofx, i.e. \(e^x\).sin(x),cos(x),tan(x)- the sine, cosine, and tangent
- Experiment using the R Console to evaluate simple arithmetic expressions. For example, find the sum and difference of 45.23 and 3.59, and the square root of 7.
- When you’re comfortable with how simple commands work, proceed to the next question.
45.23 + 3.59## [1] 48.8245.23 - 3.59## [1] 41.64sqrt(7)## [1] 2.645751When we want to save the code for our calculations or the calculation is long and requires many steps, its better to write the code in a script file in the Editor pane. Then, when the code is ready, we can evaluate it either line-by-line, or all in one go.
- Create a new R script by clicking on the corresponding menu button (in the top left); and save it somewhere in your computer.
- In the script file, write the
Rcommand to find \(\sum_{i=1}^5 i^i\). - There are many ways to evaluate the code. Rather than re-typing in the console, or copy/pasting the code,
RStudiogives us some shortcuts. First, position the text cursor on the line with the code and:- Click the
Runbutton at the top of the Editor window to execute the current line - Move the cursor back to the line of code and press
[Ctrl]+[Enter]
- Click the
# solution
1^2 + 2^2 + 3^3 + 4^4 + 5^5## [1] 3413In both cases, the line of code is copied to the console and evaluated, and the cursor advances to the next line of executable code. Pressing [Ctrl]+[Enter] will step through your code one line at a time, which is useful to find any bugs. Alternatively, to run multiple lines at once simply highlight the lines you want to run and click Run or press [Ctrl]+[Enter]. We can also save and evaluate an entire script file by pressing [Ctrl]+[Shift]+[S]. This is useful when you’ve finished a long calculation and don’t want to step through it line-by-line.
3 Variables and Vectors
During an R session we work with and create variables. Variables can be a scalars, vectors, matrices, functions, or lists. In order to create a new object we use the assign symbol <-, although one can often use = instead. For example, to create the object a with a value of 2 we can type:
a <- 2or
a = 2R has many variables and functions available by default, and many many more that can be downloaded using special libraries.
For each of these standard objects R provides online help, which can be dislpayed in the Help window. To access this help type ? followed immediately by the name of the object in question.
- R stores the value of \(\pi\) in a constant called
pi.- Display the value of \(\pi\) by evaluating
piin the console. - Use the
?to bring up the help forpi(you don’t need to read it)
- Display the value of \(\pi\) by evaluating
pi
?piVectors are the most basic type of variable in R, and all numerical variables are created as vectors - even scalars are vectors of length 1. Formally, R stores a vector as an ordered list numbers, and R contains many linear algebra tools that allow us to perform basic vector calculus (one of the many reasons why R is preferred to Excel).
The object you have just created, a, is a vector of length 1. When you type a and press [Enter] you will see the following output (without the ##):
a <- 2
aThe [1] is a number indicating which element of the vector starts the current line. In this example this is unnecessary as we only have a vector of length one. However, if we consider a bigger vector, such as the integers from 1 to 50, then we can see that the vector covers multiple lines.
1:50## [1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
## [26] 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50The most basic way to create a vector is to use th c function to ‘combine’ several values of the same type into a vector. For example,
x <- c(1,2,3)
R provides some simple functions for quickly creating numerical vectors.
We can use the colon : operator to create integer sequences between two values and return the result as a vector:
y <- 1:10
Vectors can also be combined with the c function:
z <- c(x,y)
The seq function also generates a vector containing a sequence between its two arguments from and to, but is more sophisticated than :. We can dictate the length of the sequence by supplying the optional length argument, or the step size in the sequence by passing a value to the by argument. If we supply neither length nor by, then seq gives an integer sequence like :.
y <- seq(1,9) ## same as 1:9
seq(1,10,length=25) ## sequence of given length
seq(15,45,by=3) ## sequence of given step
See the RHelp on vectors for more information.
Using the techniques above:
- Create the vector \((2, 4, 6)\) in
Rand call itv1. - Create the same vector using the object
athat you defined before, and without typing the numbers 4 or 6. Hint: multiplication also works for vectors. - Create a vector containing all of the integers from 1 to 100.
- Create a vector containing the sequence of odd numbers between 0 and 100.
- Create a vector containing your forename, middle names, and surname as a string. Hint: A string is simply some text surrounded by the quotation marks “text” or ‘text’.
Click for solution
v1 <- c(2,4,6)
a*c(1,2,3) ## or c(a,2*a,3*a)## [1] 6 4 15 3 16 61:100## [1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
## [19] 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36
## [37] 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54
## [55] 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72
## [73] 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90
## [91] 91 92 93 94 95 96 97 98 99 1002*(1:50)-1 ## many possible solutions to this one## [1] 1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 43 45 47 49
## [26] 51 53 55 57 59 61 63 65 67 69 71 73 75 77 79 81 83 85 87 89 91 93 95 97 99c('Forename',"Middle","Names","Surname")## [1] "Forename" "Middle" "Names" "Surname"\(~\)
Assigning names to the objects you create is very important so that they can be re-used. To edit or repeat previous commands in the console, we can simply press the (up arrow) and the (down arrow) keys to navigate through previous commands (e.g. to correct mistakes). However, it is often much easier to use the Editor, rather than the console, to debug any problems.
4 The durham library
Most real data will have to be imported into R from a suitable data file, or from a library or package. In these workshops, we will work with data sets stored in the ‘durham’ library. To access our datasets, we need to install the ‘durham’ package, so go to the RStudio console, and type the following:
install.packages("remotes")
remotes::install_github("louisaslett/durham-Rpkg")Now, to load the durham libarary, we use the library function and specify the library we want:
library(durham)There are many datasets in this library, to see names of them all type data(package ='durham').
For the rest of this workshop, we’ll be working with the dataset called hospital. To load a particular data set from a package, we use the data function:
data(hospital)You should now view the data (by typing hospital) and have a look at the online help using ? as before to learn about this data set.
?hospitalIf you have problems with any of the above steps, then follow the instructions on this page to load the data directly.
5 Data frames
A data frame which is a two-dimensional table of data (like a matrix) where each column contains values of one variable, and each row contains one set of values from each observation. Each column is labelled with a variable name, and the values within each column must be of the same type but the types of data held in each column can differ according to the type of variable it represents. The data set hospital that we have just loaded is a data frame.
The rows and columns of data frames can be extracted as vectors allowing us to easily perform calculations of summary statistics, for example. In the hospital data, we see that the data contains 3 columns each with different names.
We can extract individual columns from a data frame by using the variable name and the dollar-sign $. For example, to extract the beds column from hospital we would type:
hospital$beds
We can extract a vector containing all of the column names for a given data frame using the names function:
names(hospital)
- Use the
namesfunction to extract the names of the variables in the hospital data. - Create new vectors called
bedsanddiscscontaining the data for the number of beds, and number of discharges in the hospital data respectively.
Click for solution
library(durham)
data(hospital)
names(hospital)## [1] "beds" "discharges" "region"beds <- hospital$beds
discs <- hospital$dischargesWhen a vector represents numerical data, there are a number of standard functions that will be useful for any statistical calculations:
sum{#sum} sums all values in the vectormean{#mean} computes the sample mean, i.e. \(\frac{1}{n} \sum_{i=1}^n x_i\)median{#median}computes the sample median valueminandmax{#minmax} compute the sample minimum and maximumrange{#range} computes the min and max values.varandsd{#var} compute the sample variance and standard deviation, i.e. \(s^2=\frac{1}{n-1} \sum_{i=1}^n (x_i-\bar{x})^2\)quantile{#quantile} computes the min, max, median, and lower and upper quartiles. Other quantiles can be computed using theprobsargumentsummary{#summary} calculates the min, max, mean, median, and quantiles.
- Compute the mean, standard deviation and range of the discharges data.
mean(discs)## [1] 814.6031sd(discs)## [1] 589.7173range(discs)## [1] 14 28446 Simple plots
One of R’s greatest strengths is the facility it provides for producing effective graphics. In the following tasks we will use some of the key plotting tools to study the hospital data.
The plot function produces a scatterplot of its two arguments. Suppose we have saved our \(x\) coordinates in a vector a, and our \(y\) coordinates in a vector b, then to draw a scatterplot of \((x,y)\) we type
plot(x=a, y=b)
If the argument labels x and y are not supplied, R will assume the first argument is x and the second is y. If only one vector of data is supplied, this will be taken as the \(y\) value and will be plotted against the integers 1:length(y), i.e. in the sequence in which they appear in the data.
All of the standard plot functions can be customised by passing additional arguments to the function. For instance, we can add a plot title and axis labels by supplying optional arguments:
main- provides a title to display at the top of the plotxlab- provides a label for the horizontal axisylab- provides a label for the vertical axis
For example,
plot(x=a,y=b, xlab='A', ylab='B', main='Plot of B vs A')
Note: Once a plot has been drawn, it is not possible to erase any features from it - we can only add extra lines or points to it. So, if you make a mistake drawing your plot then you’ll need to start over with a fresh one by calling plot again.
- Produce a scatter-plot of discharges (vertically) against beds (horizontally) using
plot. The scatterplot will appear in the ‘Plots’ sub-window. - Redraw the plot, labelling the axes
BedsandDischarges. - What do you notice about the relationship?
Click for solution
plot(y=discs, x=beds)
plot(y=discs, x=beds, xlab='Beds', ylab='Discharges') # again, with labels
A histogram consists of parallel vertical bars that graphically shows the frequency distribution of a quantitative variable. The area of each bar is proportional to the frequency of items found in each class. To plot a histogram, we use the hist function and apply it to a single vector of data
hist(x)
As with plot, we can use main and xlab to set the plot title and horizontal axis label.
Histogram also takes a number of arguments specific to the plotting of histograms:
breaks- allows us to control the number of bars in the histogram. Ifbreaksis set to a single number, this will be used to (suggest) the number of bars in the histogram. Ifbreaksis set to a vector, the values will be used to indicate the endpoints of the bars of the histogram. Note:Rinterprets this number as a suggestion only.freq- ifTRUEthe histogram shows the simple frequencies or counts within each bar; ifFALSEthen the histogram shows frequency densities rather than counts.
- Produce a histogram of
dischargesfrom thehospitaldata. - Produce a histogram of the
bedsdata. What do you notice about the two variables? - Increase the number of bars in the discharges histogram. Does this change your perception of the distribution of the discharges data. How about if you decrease the number of cells?
Click for solution
hist(discs)
hist(beds)
## experiment with different numbers of bars
hist(discs,breaks=20)
hist(discs,breaks=50)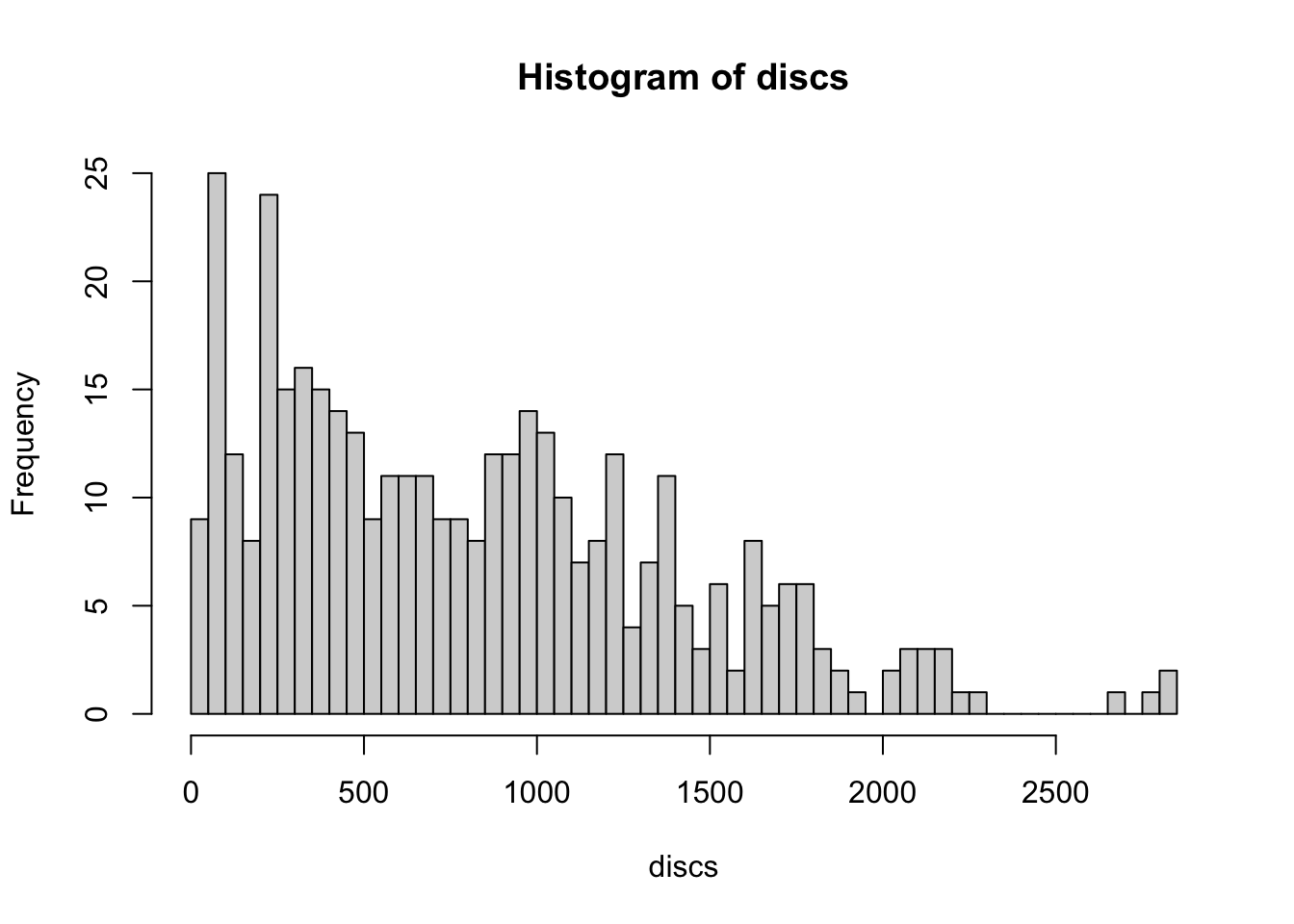
A boxplot provides a graphical view of the median, quartiles, maximum, and minimum of a data set. A box plot is a bit like a histogram seen from above. The full name is ‘box and whisker’ plot. The ‘box’ shows the middle 50% of the observations, from the first to the third quartile. Inside the box, the line shows the median (which is the second quartile). The ‘whiskers’ show the full range of the data, although in R there is the possibility of excluding outliers, which appear as individual points.
To draw a boxplot of a single variable we simply pass the data directly to the boxplot function:
boxplot(x)
To draw multiple boxplots within the same plot, we can pass multiple vectors separated by commas as arguments (e.g. boxplot(x,y,z)). We can even pass an entire dataframe to the boxplot function, and it will draw boxplots of all the columns within a single plot.
- Draw a boxplot of the discharges data. Compare this to the Histogram of discharges.
- Draw a boxplot of the beds and discharges data on the same y-axis using the boxplot function only once.
Click for solution
# (a)
boxplot(discs) 
boxplot(discs, xlab="Discharges")
#(b)
boxplot(beds, discs)
boxplot(beds, discs, names=c("Bed","Discharges"))
\(~\)