Lab 6
Tahani Coolen-Maturi
This computer practical is based on Chapters 2 and 3 from the ISL book. James, Witten, Hastie, and Tibshirani (2013). An Introduction to Statistical Learning: with Applications in R.
To start, create a new R script by clicking on the corresponding menu button
(in the top left); and save it somewhere in your computer. You can now write all your code into this file, and then execute
it in R using the menu button Run or by simple pressing ctrl \(+\) enter.
1 Boston Housing Data
In this computer practical, we will use the Boston data set (from the MASS package), which consists of 506 observations concerning housing values in the area of Boston. We are interested in predicting the median house value medv using the 13 predictor variables; such as crim (per capita crime rate by town), rm (average number of rooms per house), age (average age of houses), and lstat (percent of households with low socioeconomic status).
\(~\)
First, we need to install the MASS package, using the command install.packages("MASS"). We only need to do this once.
Now, load the package and the data set:
library(MASS)
data("Boston")
attach(Boston)1.1 Exploratory data analysis
To get more information about the data set:
names(Boston)## [1] "lcrim" "zn" "indus" "chas" "nox" "rm" "age" "disf" "rad" "tax" "ptratio"
## [12] "black" "lstat" "medv"?Boston
str(Boston)## 'data.frame': 506 obs. of 14 variables:
## $ lcrim : num -5.06 -3.6 -3.6 -3.43 -2.67 ...
## $ zn : num 18 0 0 0 0 0 12.5 12.5 12.5 12.5 ...
## $ indus : num 2.31 7.07 7.07 2.18 2.18 2.18 7.87 7.87 7.87 7.87 ...
## $ chas : int 0 0 0 0 0 0 0 0 0 0 ...
## $ nox : num 0.538 0.469 0.469 0.458 0.458 0.458 0.524 0.524 0.524 0.524 ...
## $ rm : num 6.58 6.42 7.18 7 7.15 ...
## $ age : num 34.8 21.1 38.9 54.2 45.8 ...
## $ disf : int 2 2 2 3 3 3 3 3 3 3 ...
## $ rad : int 1 2 2 3 3 3 5 5 5 5 ...
## $ tax : int 296 242 242 222 222 222 311 311 311 311 ...
## $ ptratio: num 15.3 17.8 17.8 18.7 18.7 18.7 15.2 15.2 15.2 15.2 ...
## $ black : num 397 397 393 395 397 ...
## $ lstat : num 4.98 9.14 4.03 2.94 5.33 ...
## $ medv : num 24 21.6 34.7 33.4 36.2 28.7 22.9 27.1 16.5 18.9 ...# Look at the first few rows
head(Boston)## lcrim zn indus chas nox rm age disf rad tax ptratio black lstat medv
## 1 -5.064036 18 2.31 0 0.538 6.575 34.8 2 1 296 15.3 396.90 4.98 24.0
## 2 -3.600502 0 7.07 0 0.469 6.421 21.1 2 2 242 17.8 396.90 9.14 21.6
## 3 -3.601235 0 7.07 0 0.469 7.185 38.9 2 2 242 17.8 392.83 4.03 34.7
## 4 -3.430523 0 2.18 0 0.458 6.998 54.2 3 3 222 18.7 394.63 2.94 33.4
## 5 -2.672924 0 2.18 0 0.458 7.147 45.8 3 3 222 18.7 396.90 5.33 36.2
## 6 -3.511570 0 2.18 0 0.458 6.430 41.3 3 3 222 18.7 394.12 5.21 28.7# Summary statistics
summary(Boston)## lcrim zn indus chas nox rm
## Min. :-5.0640 Min. : 0.00 Min. : 0.46 Min. :0.00000 Min. :0.3850 Min. :3.561
## 1st Qu.:-2.5005 1st Qu.: 0.00 1st Qu.: 5.19 1st Qu.:0.00000 1st Qu.:0.4490 1st Qu.:5.886
## Median :-1.3606 Median : 0.00 Median : 9.69 Median :0.00000 Median :0.5380 Median :6.208
## Mean :-0.7804 Mean : 11.36 Mean :11.14 Mean :0.06917 Mean :0.5547 Mean :6.285
## 3rd Qu.: 1.3021 3rd Qu.: 12.50 3rd Qu.:18.10 3rd Qu.:0.00000 3rd Qu.:0.6240 3rd Qu.:6.623
## Max. : 4.4884 Max. :100.00 Max. :27.74 Max. :1.00000 Max. :0.8710 Max. :8.780
## age disf rad tax ptratio black lstat
## Min. : 0.000 Min. :1.00 Min. : 1.000 Min. :187.0 Min. :12.60 Min. : 0.32 Min. : 1.73
## 1st Qu.: 5.925 1st Qu.:1.00 1st Qu.: 4.000 1st Qu.:279.0 1st Qu.:17.40 1st Qu.:375.38 1st Qu.: 6.95
## Median :22.500 Median :2.00 Median : 5.000 Median :330.0 Median :19.05 Median :391.44 Median :11.36
## Mean :31.425 Mean :1.96 Mean : 9.549 Mean :408.2 Mean :18.46 Mean :356.67 Mean :12.65
## 3rd Qu.:54.975 3rd Qu.:3.00 3rd Qu.:24.000 3rd Qu.:666.0 3rd Qu.:20.20 3rd Qu.:396.23 3rd Qu.:16.95
## Max. :97.100 Max. :4.00 Max. :24.000 Max. :711.0 Max. :22.00 Max. :396.90 Max. :37.97
## medv
## Min. : 5.00
## 1st Qu.:17.02
## Median :21.20
## Mean :22.53
## 3rd Qu.:25.00
## Max. :50.00# Check for missing values
sum(is.na(Boston))## [1] 0# zero here, so no missing values\(~\)
The following exercise is Question 10, Chapter 2, from the ISL book.
- How many rows are in this data set? How many columns? What do the rows and columns represent?
- Make some pairwise scatterplots of the predictors (columns) in this data set. Describe your findings.
- Are any of the predictors associated with per capita crime rate? If so, explain the relationship.
Click for solution
## SOLUTION
# (a)
dim(Boston)## [1] 506 14# 506 observations and 14 variables
# (b)
pairs(Boston)
# (c)
# Add correlation coefficients
# Correlation panel
panel.cor <- function(x, y){
usr <- par("usr"); on.exit(par(usr))
par(usr = c(0, 1, 0, 1))
r <- round(cor(x, y), digits=2)
txt <- paste0("r = ", r)
cex.cor <- 0.8/strwidth(txt)
text(0.5, 0.5, txt, cex = cex.cor * r)
}
# Customize upper panel
upper.panel<-function(x, y){
points(x,y, pch = 19)
}
# Create the plots
pairs(Boston,
lower.panel = panel.cor,
upper.panel = upper.panel)
# A nicer plot using the corrplot package.
#install.packages("corrplot")
library(corrplot)
#checking correlation between variables
corrplot(cor(Boston), method = "number", type = "upper", diag = FALSE)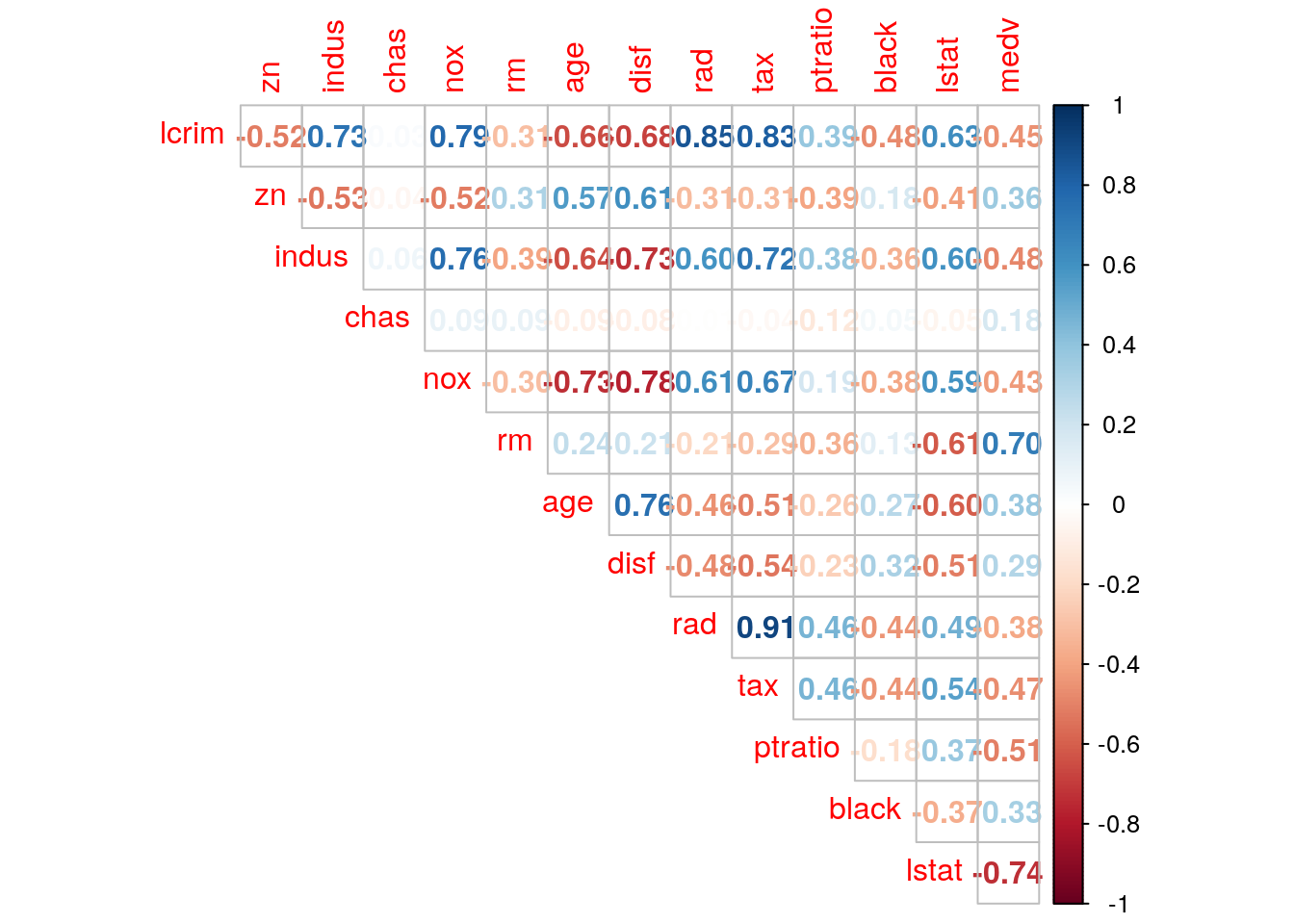
corrplot.mixed(cor(Boston), upper = "ellipse", lower = "number",number.cex = .7)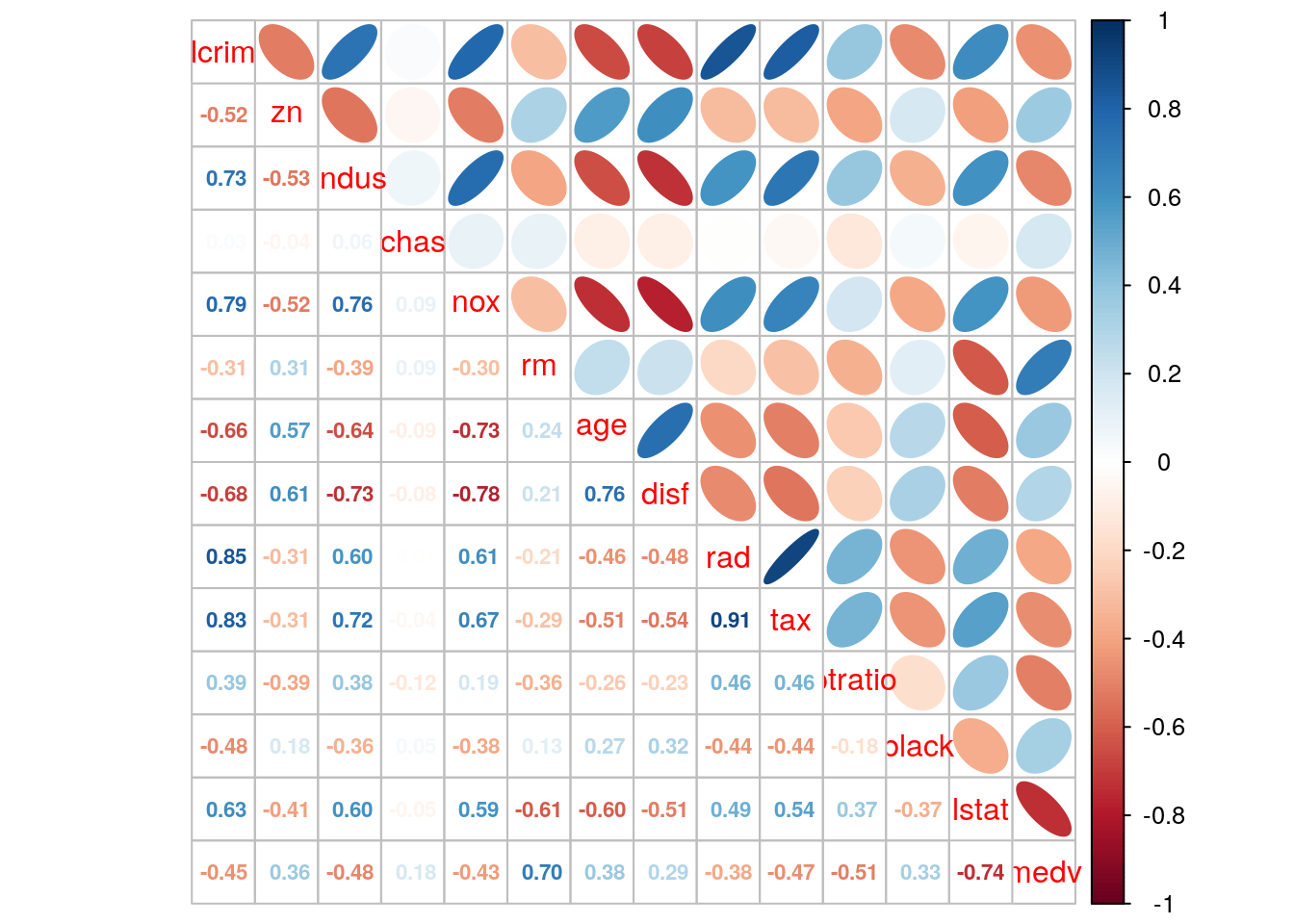
\(~\)
2 Simple Linear Regression
This section is based on Lab 3.6, pages 109-119, from the ISL book. For more information, see Lab 5 or Linear regression.
2.1 Linear regression model fitting
- Use the
lm()function to fit a simple linear regression model, withmedvas the response variable andlstatas the predictor variable. Save the result of the regression function toreg1. - Use
summary(reg1)command to get information about the model. This gives us the estimated coefficients, t-tests, p-values and standard errors as well as the R-square and F-statistic for the model. - Use
names(reg1)function to find what types of information are stored inreg1. For example, we can get or extract the estimated coefficients using the functioncoef(reg1)orreg1$coefficients.
Click for solution
## SOLUTION
# (a)
reg1 <- lm(medv~lstat,data=Boston)
# (b)
summary(reg1)##
## Call:
## lm(formula = medv ~ lstat, data = Boston)
##
## Residuals:
## Min 1Q Median 3Q Max
## -15.168 -3.990 -1.318 2.034 24.500
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 34.55384 0.56263 61.41 <0.0000000000000002 ***
## lstat -0.95005 0.03873 -24.53 <0.0000000000000002 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 6.216 on 504 degrees of freedom
## Multiple R-squared: 0.5441, Adjusted R-squared: 0.5432
## F-statistic: 601.6 on 1 and 504 DF, p-value: < 0.00000000000000022# (c)
names(reg1)## [1] "coefficients" "residuals" "effects" "rank" "fitted.values" "assign" "qr"
## [8] "df.residual" "xlevels" "call" "terms" "model"coef(reg1)## (Intercept) lstat
## 34.5538409 -0.9500494reg1$coefficients## (Intercept) lstat
## 34.5538409 -0.9500494\(~\)
2.2 Confidence and prediction intervals
- Obtain a 95% confidence interval for the coefficient estimates. Hint: use the
confint()command. - Obtain a 95% confidence and prediction intervals of
medvfor a given value oflstat. Assume this given value oflstatis equal to 10.
Click for solution
## SOLUTION
# (a)
confint(reg1, level = 0.95)## 2.5 % 97.5 %
## (Intercept) 33.448457 35.6592247
## lstat -1.026148 -0.8739505# (b)
newdata= data.frame(lstat=10)
predict(reg1,newdata=newdata, interval="confidence", level = 0.95)## fit lwr upr
## 1 25.05335 24.47413 25.63256predict(reg1,data.frame(lstat=10), interval="prediction", level = 0.95)## fit lwr upr
## 1 25.05335 12.82763 37.27907\(~\)
2.3 Regression diagnostics
- Create a scatterplot of
lstatandmedv. Is there a relationship between the two variables? - Plot
medvandlstatalong with the least squares regression line using theplot()andabline()functions. - Use residual plots to check the assumptions of the model.
Click for solution
## SOLUTION
# (a) & (b)
plot(lstat,medv, pch=16, col="cornflowerblue")
abline(reg1,lwd=3,col="red")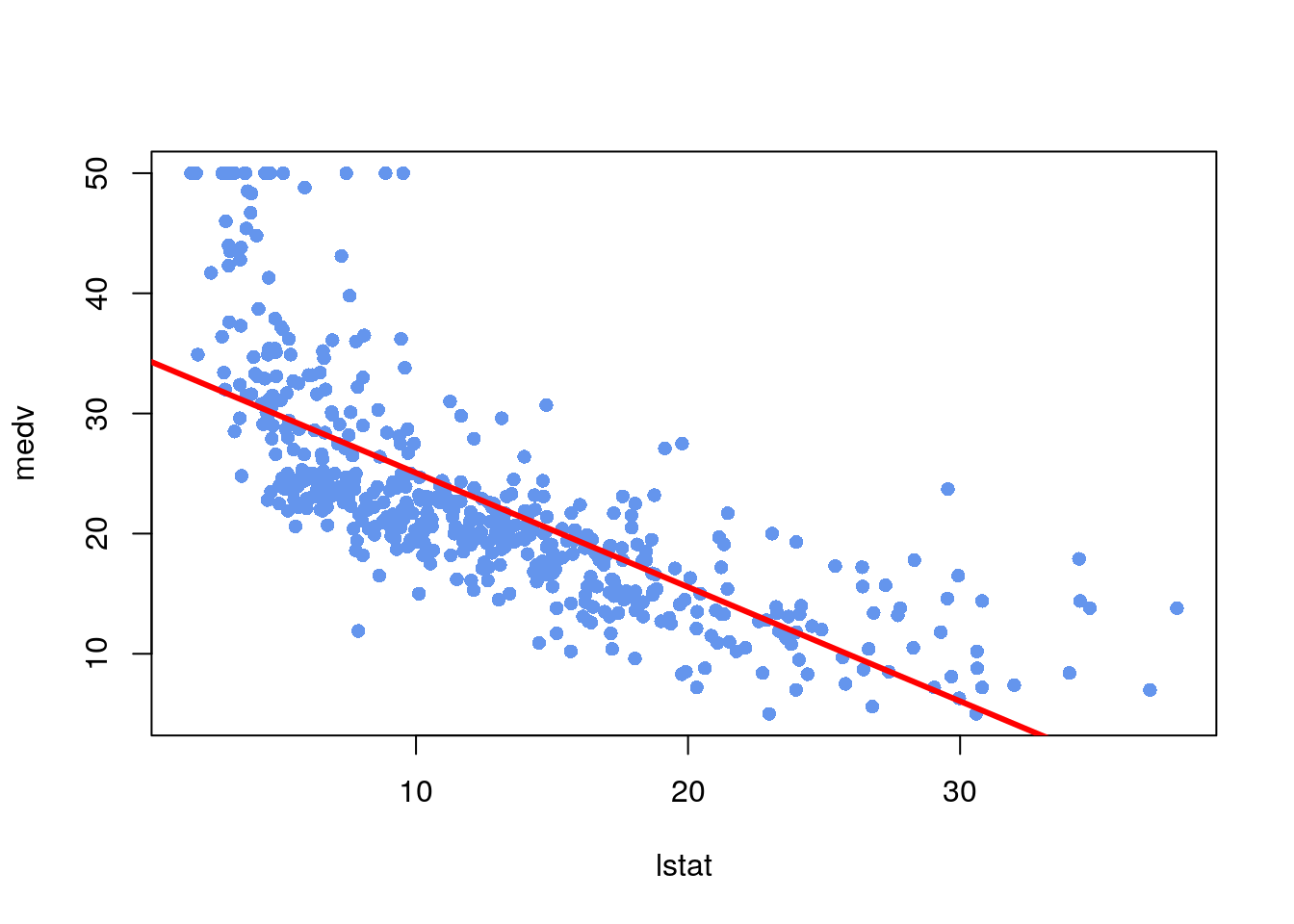
# (c)
par(mfrow=c(1,2)) # to have two plots side-by-side
plot(reg1, which=1, pch=16, col="cornflowerblue")
plot(reg1, which=2, pch=16, col="cornflowerblue")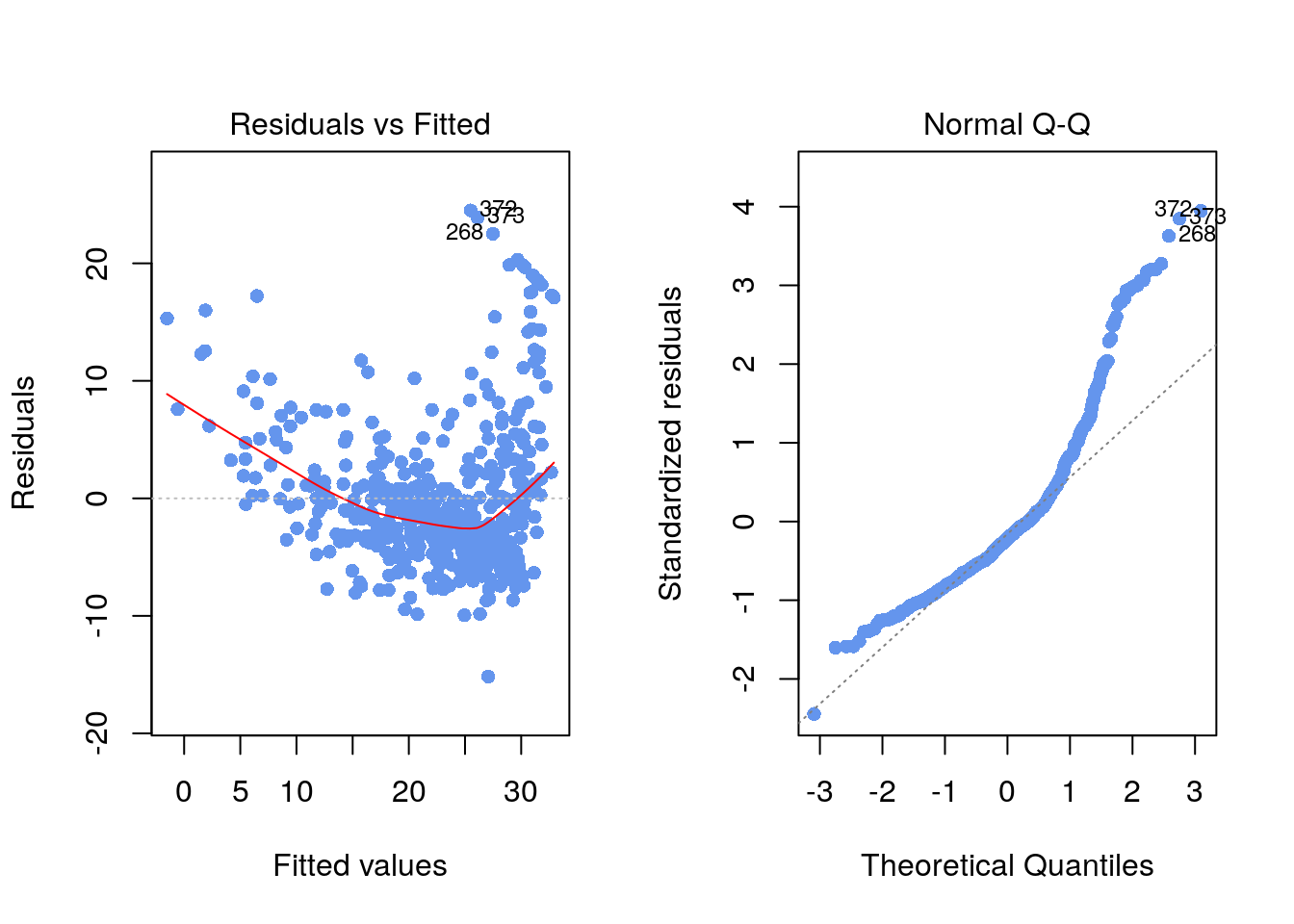
par(mfrow=c(1,1)) # to return to one plot per window
par(mfrow=c(2,2))
plot(reg1, pch=16, col="green")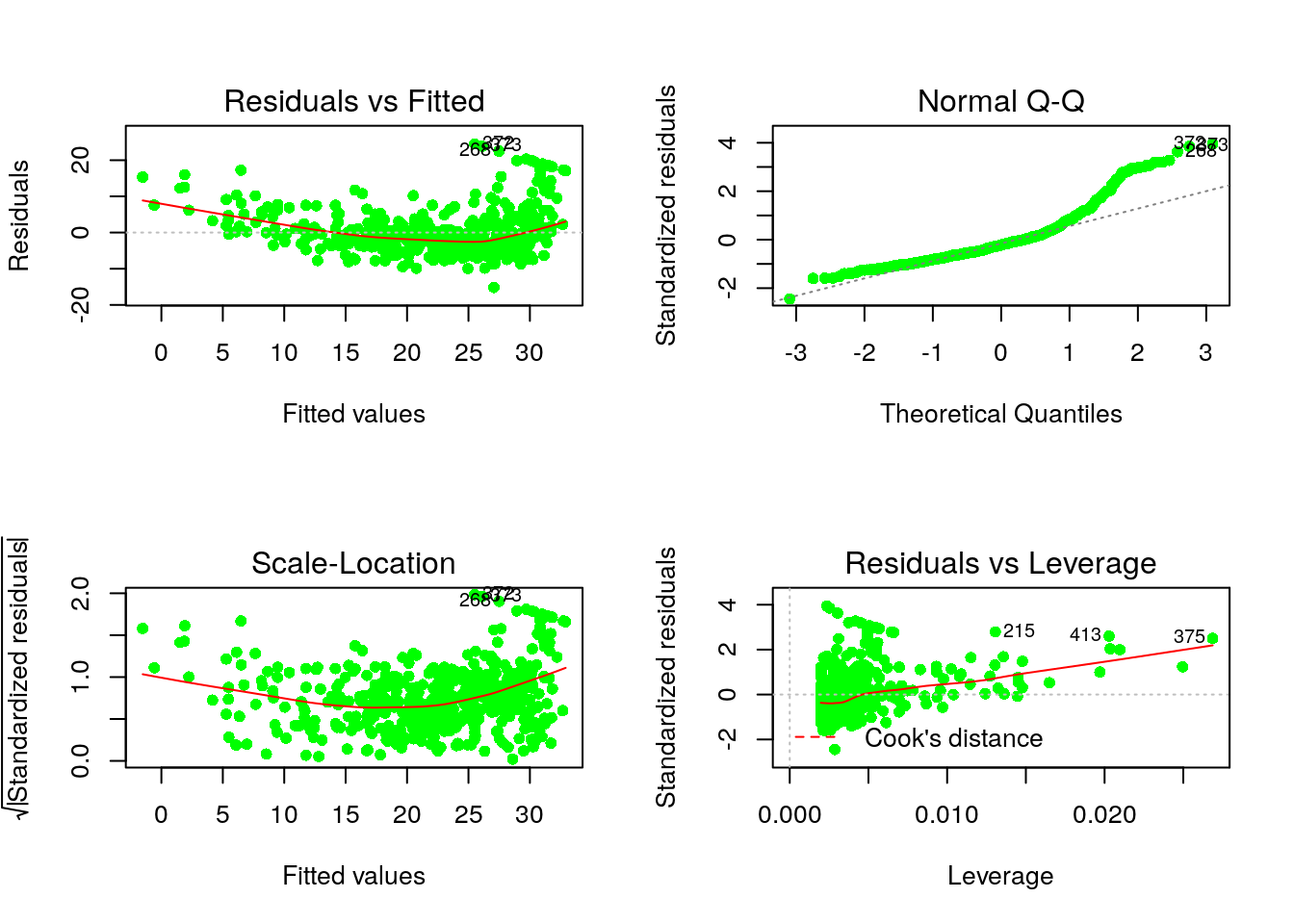
par(mfrow=c(1,1))\(~\)
3 Multiple Linear Regression
3.1 Linear regression model fitting
- Use the
lm()function again to fit a linear regression model, withmedvas the response variable and bothlstatandageas predictors. Save the result of the regression function toreg2. - Now use the
lm()function again to fit a linear regression model, withmedvas the response variable and all other 13 variables as predictors. Save the result of the regression function toreg3. Hint: Uselm(medv~., data=Boston). - Fit the same linear regression as in (b) but now exclude the age. Save the result of the regression function to
reg4. Hint: Uselm(medv~.-age, data=Boston). - Compare the R-squares of these models. Notice we can extract the R-square value from the summary object as
summary(reg)$r.sq. Type?summary.lmto see what else is available. - Use Variance Inflation Factor (VIF) to assess if there is any relationship between the independent variables. Hint: use the
vif()function from thecarpackage.
Click for solution
## SOLUTION
# (a)
reg2 <- lm(medv~lstat+age,data=Boston)
summary(reg2)##
## Call:
## lm(formula = medv ~ lstat + age, data = Boston)
##
## Residuals:
## Min 1Q Median 3Q Max
## -15.981 -3.978 -1.283 1.968 23.158
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 36.67719 0.93644 39.166 < 0.0000000000000002 ***
## lstat -1.03207 0.04819 -21.416 < 0.0000000000000002 ***
## age -0.03454 0.01223 -2.826 0.00491 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 6.173 on 503 degrees of freedom
## Multiple R-squared: 0.5513, Adjusted R-squared: 0.5495
## F-statistic: 309 on 2 and 503 DF, p-value: < 0.00000000000000022# (b)
reg3 <- lm(medv~.,data=Boston)
summary(reg3)##
## Call:
## lm(formula = medv ~ ., data = Boston)
##
## Residuals:
## Min 1Q Median 3Q Max
## -15.9417 -2.7657 -0.6291 1.8588 27.3393
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 34.191898 5.664351 6.036 0.00000000310693 ***
## lcrim 0.337671 0.287002 1.177 0.239945
## zn 0.024095 0.013805 1.745 0.081554 .
## indus 0.035763 0.064568 0.554 0.579907
## chas 2.968165 0.891291 3.330 0.000933 ***
## nox -16.083535 4.083729 -3.938 0.00009385967653 ***
## rm 3.988555 0.432333 9.226 < 0.0000000000000002 ***
## age -0.004947 0.013922 -0.355 0.722502
## disf -2.125253 0.466705 -4.554 0.00000665177553 ***
## rad 0.226836 0.078335 2.896 0.003951 **
## tax -0.012431 0.003894 -3.192 0.001503 **
## ptratio -0.990292 0.135717 -7.297 0.00000000000119 ***
## black 0.011723 0.002794 4.196 0.00003222736047 ***
## lstat -0.560519 0.052456 -10.686 < 0.0000000000000002 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 4.915 on 492 degrees of freedom
## Multiple R-squared: 0.7218, Adjusted R-squared: 0.7145
## F-statistic: 98.2 on 13 and 492 DF, p-value: < 0.00000000000000022# (c)
reg4 <- lm(medv~.-age,data=Boston)
summary(reg4)##
## Call:
## lm(formula = medv ~ . - age, data = Boston)
##
## Residuals:
## Min 1Q Median 3Q Max
## -16.0213 -2.7773 -0.6448 1.8600 27.5147
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 33.630101 5.434388 6.188 0.00000000127944 ***
## lcrim 0.348077 0.285251 1.220 0.22295
## zn 0.023438 0.013669 1.715 0.08703 .
## indus 0.035055 0.064480 0.544 0.58692
## chas 2.986836 0.888952 3.360 0.00084 ***
## nox -15.774595 3.986559 -3.957 0.00008706479949 ***
## rm 4.019564 0.423058 9.501 < 0.0000000000000002 ***
## disf -2.177808 0.442255 -4.924 0.00000115687834 ***
## rad 0.224004 0.077859 2.877 0.00419 **
## tax -0.012391 0.003889 -3.186 0.00153 **
## ptratio -0.986774 0.135235 -7.297 0.00000000000119 ***
## black 0.011820 0.002778 4.255 0.00002504988298 ***
## lstat -0.554490 0.049591 -11.181 < 0.0000000000000002 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 4.91 on 493 degrees of freedom
## Multiple R-squared: 0.7217, Adjusted R-squared: 0.715
## F-statistic: 106.6 on 12 and 493 DF, p-value: < 0.00000000000000022# (d)
summary(reg1)$r.sq## [1] 0.5441463summary(reg2)$r.sq## [1] 0.5512689summary(reg3)$r.sq## [1] 0.7218163summary(reg4)$r.sq## [1] 0.7217449summary(reg4)$r.squared## [1] 0.7217449# or the adjusted R Squared
summary(reg4)$adj.r.squared## [1] 0.714972# (e)
#install.packages("car") # you need to do this once
library(car)
vif(reg3)## lcrim zn indus chas nox rm age disf rad tax ptratio black
## 8.050682 2.167545 4.102554 1.071561 4.682142 1.929327 3.211046 3.798600 9.727486 9.007856 1.805069 1.360248
## lstat
## 2.933857\(~\)
If you have time left, you can try the following:
\(~\)
3.2 Interaction between variables
It is straightforward to include the interaction between variables in the linear model using the lm() function. For example, the syntax lstat*age will include lstat, age and the interaction term lstat x age as predictors.
summary(lm(medv~lstat*age, data=Boston))##
## Call:
## lm(formula = medv ~ lstat * age, data = Boston)
##
## Residuals:
## Min 1Q Median 3Q Max
## -15.806 -4.045 -1.333 2.085 27.552
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 36.0164500 0.9780721 36.824 <0.0000000000000002 ***
## lstat -0.9765217 0.0540041 -18.082 <0.0000000000000002 ***
## age 0.0007209 0.0198792 0.036 0.9711
## lstat:age -0.0041560 0.0018518 -2.244 0.0252 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 6.149 on 502 degrees of freedom
## Multiple R-squared: 0.5557, Adjusted R-squared: 0.5531
## F-statistic: 209.3 on 3 and 502 DF, p-value: < 0.00000000000000022We can also include a non-linear transformation of the predictors, using the function I(). For example, we can regress the response variable medv on both lstat and lstat^2 as follows.
summary(lm(medv~lstat+I(lstat^2), data=Boston))##
## Call:
## lm(formula = medv ~ lstat + I(lstat^2), data = Boston)
##
## Residuals:
## Min 1Q Median 3Q Max
## -15.2834 -3.8313 -0.5295 2.3095 25.4148
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 42.862007 0.872084 49.15 <0.0000000000000002 ***
## lstat -2.332821 0.123803 -18.84 <0.0000000000000002 ***
## I(lstat^2) 0.043547 0.003745 11.63 <0.0000000000000002 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 5.524 on 503 degrees of freedom
## Multiple R-squared: 0.6407, Adjusted R-squared: 0.6393
## F-statistic: 448.5 on 2 and 503 DF, p-value: < 0.00000000000000022If we are interested in a higher-order polynomial then it is best to use the poly() function within the lm() function. For example, we use the command below if we are interested in the fifth-order polynomial fit of the lstat, where again the medv is the response variable.
summary(lm(medv~poly(lstat,5), data=Boston))##
## Call:
## lm(formula = medv ~ poly(lstat, 5), data = Boston)
##
## Residuals:
## Min 1Q Median 3Q Max
## -13.5433 -3.1039 -0.7052 2.0844 27.1153
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 22.5328 0.2318 97.197 < 0.0000000000000002 ***
## poly(lstat, 5)1 -152.4595 5.2148 -29.236 < 0.0000000000000002 ***
## poly(lstat, 5)2 64.2272 5.2148 12.316 < 0.0000000000000002 ***
## poly(lstat, 5)3 -27.0511 5.2148 -5.187 0.00000031 ***
## poly(lstat, 5)4 25.4517 5.2148 4.881 0.00000142 ***
## poly(lstat, 5)5 -19.2524 5.2148 -3.692 0.000247 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 5.215 on 500 degrees of freedom
## Multiple R-squared: 0.6817, Adjusted R-squared: 0.6785
## F-statistic: 214.2 on 5 and 500 DF, p-value: < 0.00000000000000022Finally, we can also apply other transformations, e.g. taking the log of rm (average number of rooms per dwelling).
summary(lm(medv~log(rm), data=Boston))##
## Call:
## lm(formula = medv ~ log(rm), data = Boston)
##
## Residuals:
## Min 1Q Median 3Q Max
## -19.487 -2.875 -0.104 2.837 39.816
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -76.488 5.028 -15.21 <0.0000000000000002 ***
## log(rm) 54.055 2.739 19.73 <0.0000000000000002 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 6.915 on 504 degrees of freedom
## Multiple R-squared: 0.4358, Adjusted R-squared: 0.4347
## F-statistic: 389.3 on 1 and 504 DF, p-value: < 0.00000000000000022\(~\)